
OS Notes
 https://youtube.com/playlist?list=PL1NlEMiEIOdHYbmz2XBI7YZPZb6XsxyLX
https://youtube.com/playlist?list=PL1NlEMiEIOdHYbmz2XBI7YZPZb6XsxyLX

Chapter 1: Operating System
- CPU is the brain of the Computer
- Memory stores the running programs
- System bus: wires to connect many PC's parts
- Instructions need to be loaded into memory to be executed later.
- CPU includes:
- PC: program counter
- IR: instruction register
- MAR: memory address register
- MBR: memory buffer register
- I/O AR: I/O address register
- I/O BR: I/O buffer register
- Memory hierarchy
- Primary:
- Register
- Cache
- Main memory
- Secondary:
- Nonvolatile memory
- Hard-disk memory
- Tertiary:
- Optical disk
- Magnetic tapes
- Primary:
- Computer Architecture: single/multiprocessors, clusters...
- Core is the component that executes instructions and has registers for storing data locally
- When the program is running: Fetch → Decode (control signal) → Execute (run) → Fetch → ....
- What is the OS?
- User view: making sure the system operates correctly and efficiently in an easy-to-use manner
- System review:
- Resource manager/allocator
- Control program
- OS as a kernel (the one program running at all times on the computer)
- Three key ideas:
- Virtualization
- Keyword: share
- OS takes physical resource: processor, memory, disk and transform it into a more general, powerful, and easy to itself
- OS provides some APIs: System calls (standard library to application) → to use keyboards...
kill $(jobs -p) # kill all background processes gcc -o cpu cpu.c -Wall # compile cpu.c -> cpu with all warnings jobs # show tasks running in the background jg # run foreground- The OS decides which program out of many programs should be run based on its policy (scheduler)
- Shared memory:
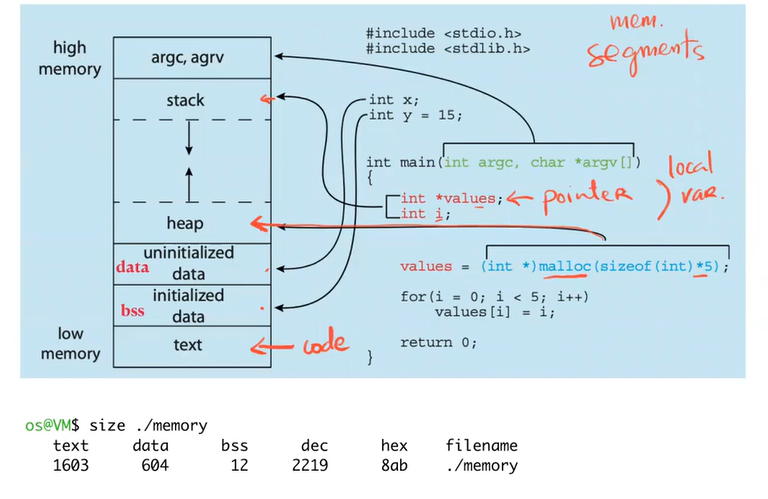
#include <unistd.h> #include <stdio.h> #include <stdlib.h> #include "common.h" int main(int argc, char *argv[]){ if (argc != 2) {fprintf(stderr, "usage: mem <value>\n"); exit(1);} int *p; p = malloc(sizeof(int)); assert(p != NULL); printf("(%d) addr pointed to by p: %p\n", (int) getpid(), p); *p = atoi(argv[1]); while(1) { Spin(1); *p = *p + 1; printf("(%d) value of p: %d\n", getpid(), *p); } return 0; }gcc -o mem mem.c -Wall ./mem 5 (6985) addr pointed to by p: 0x55a3492fa2a0 (6985) value of p: 6 (6985) value of p: 7 (6985) value of p: 8 (6985) value of p: 9 (6985) value of p: 10 (6985) value of p: 11 ^C- The OS give illusions to the program to make it think it own the whole memory
⇒ OS as a resource manager:
- Share CPU ⇒ virtualize CPU
- Share memory ⇒ virtualize memory
- Concurrency
- Problems arise when working on many things at once
- Multi-thread programs exhibit the same problems: program stopped before some threads finish
- Persistence
- No virtualize disk for each application: how
- Handling problems with journaling or copy-on-write
- Virtualization
- Design goal:
- Build up some abstraction
- Performance: minimize the overheads of the OS
- Provide protection between applications and between OS and applications
- Reliability
- Security
- Mobility
Chapter 2: Processes
- The abstraction - Process
- Multiple programs running → the resources are shared
- Process model
- A process is an instance of a running program
- Each process has its own virtual CPU
- How to virtualize CPU?
- mechanism = context switch
- Sharing:
- Time sharing → CPU
- Space sharing → Memory
- Cannot share the program counter → If share, the programs run sequentially ⇒ save-restore... in every time the PC switches between processes
- Context switch:
- Context: machine state in which process runs
- Switch between machine state = save and restore the machine state
- Multiprogramming: rapid switching back and forth between processes
- Logical program counter is loaded into physical program counter when a process run
- What constitute a process?
- Machine state: what a process can read/update when running
- Memory address space which is a list of memory allocation from 0 to some maximum at the process can read/write
- Address space contain executable program, program data, and its stack
- Register: PC, stack pointer, frame pointer...
- Persistent storage devices: a list of opened files.
- Memory address space which is a list of memory allocation from 0 to some maximum at the process can read/write
- Machine state: what a process can read/update when running
- Process API: Interface of an OS
- Create process
- Load code and data into the memory
- Then the CPU fetches the instructions, then decodes, and then executes
- Note: the OS loads the address space into memory
- Address space can be bigger than the physical memory
Process creating
- Loading code and static data into memory
- Create and initialize a stack
- I/O set up (open files...)
- Start the program running at entry point
main()- point the PC to themain()code in memory - put the address of PC ofmain()into PC
Layout of a process
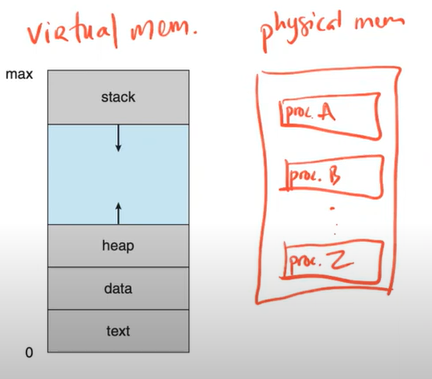
The process thinks that its address space starts from 0 to the maximum value - Text section - the executable code
- Data section - global variables
- Run-time stack - temp data storage when invoking functions: function parameters, return addresses, local variable...
- Heap - used for dynamically-allocated data during program runtime (
malloc()andfree())
Layout of virtual memory of a process
- Destroy
- Wait
- Miscellaneous (#) Control
- Status
- Process States:
- Running actually using CPU at the instant
- actually using CPU at the instant, executing instructions
- Ready
- runnable/ready to run; temporarily stopped to let another process run
- Block
- not ready; unable to run until some external event happens
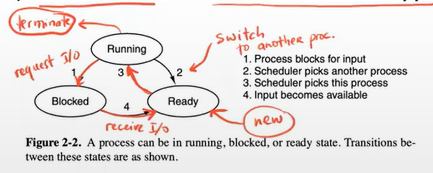
The new process → Running [(→ or Switch to another process (2) ) || (→ Blocked to Wait for I/O s → Ready) || (→ Terminate at the end of the process)] - Running actually using CPU at the instant
- Process States:
Process API
- fork()
- To create a new process
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int main(int argc, char *argv[]) { printf("hello world (pid:%d)\n", (int) getpid()); int rc = fork(); if (rc < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child (new process) printf("hello, I am child (pid:%d)\n", (int) getpid()); } else { // parent goes down this path (original process) printf("hello, I am parent of %d (pid:%d)\n", rc, (int) getpid()); } return 0; }Hint
- If in child, then rc == 0
- If in parent, then rc == child pid
- Child process has its own
- address space
- registers
- different rc value
- the same text segment
- wait()
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/wait.h> int main(int argc, char *argv[]) { printf("hello world (pid:%d)\n", (int) getpid()); int rc = fork(); if (rc < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child (new process) printf("hello, I am child (pid:%d)\n", (int) getpid()); sleep(1); } else { // parent goes down this path (original process) int wc = wait(NULL); // system call printf("hello, I am parent of %d (wc:%d) (pid:%d)\n", rc, wc, (int) getpid()); } return 0; }
- exec()
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <sys/wait.h> int main(int argc, char *argv[]) { printf("hello world (pid:%d)\n", (int) getpid()); int rc = fork(); if (rc < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child (new process) printf("hello, I am child (pid:%d)\n", (int) getpid()); char *myargs[3]; myargs[0] = strdup("wc"); // program: "wc" (word count) myargs[1] = strdup("p3.c"); // argument: file to count myargs[2] = NULL; // marks end of array execvp(myargs[0], myargs); // runs word count printf("this shouldn't print out"); } else { // parent goes down this path (original process) int wc = wait(NULL); printf("hello, I am parent of %d (wc:%d) (pid:%d)\n", rc, wc, (int) getpid()); } return 0; }#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> #include <assert.h> #include <sys/wait.h> int main(int argc, char *argv[]) { int rc = fork(); if (rc < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child: redirect standard output to a file close(STDOUT_FILENO); open("./p4.output", O_CREAT|O_WRONLY|O_TRUNC, S_IRWXU); // now exec "wc"... char *myargs[3]; myargs[0] = strdup("wc"); // program: "wc" (word count) myargs[1] = strdup("p4.c"); // argument: file to count myargs[2] = NULL; // marks end of array execvp(myargs[0], myargs); // runs word count } else { // parent goes down this path (original process) int wc = wait(NULL); assert(wc >= 0); } return 0; }
- fork()
execfamily- v: array params
- l: list of arguments
- e: environments
- p: path
- ...
How to switch between processes? MECHANISM - Limited Direct Execution
- Challenges in virtualizing CPU:
- Has good performance
- Retain control
Direct Execution Protocol (Without Limits)
💡The OS transfers control to the program to use the CPU and vice versaProblems with the Direct Execution Protocol
- Ensure the program doesn't do any "unwanted" things
- How to stop the running process to switch to another process?
How to resolve the problems?
Problem 1: Restricted operations
Most computers have two modes of operation:
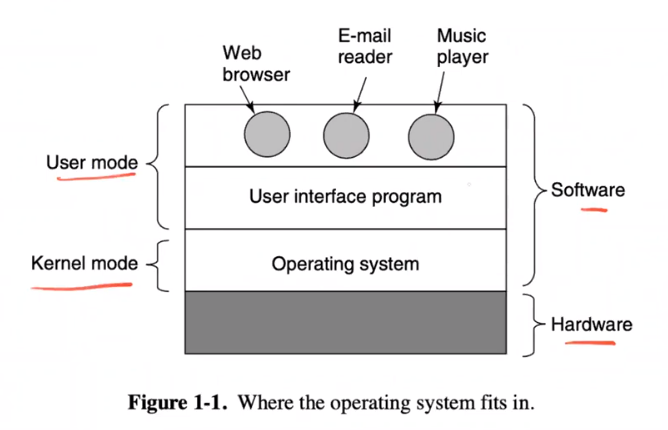
Kernel-mode - also called supervisor mode
Has complete access to all the hardware and can execute any instruction the machine is capable of executing including privileged operations like I/O requests
User-mode
- Only a subset of the machine instructions is available
- Those instructions that affect control of the machine or do I/O are forbidden to user-mode program
System calls provide user programs an interface to perform privileged operations:
read(); write(); fork(); wait(); exec();Trap instruction raises the privileged level to kernel mode to execute system call
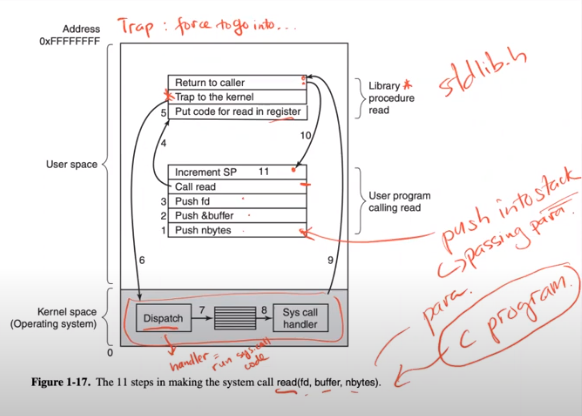
Kernel stack used to store program counter, flags, and a few other registers when executing trap execution
Return-from-trap instruction pops those values from the kernel stack and resumes execution of the user-mode program
Problem 2: Switching between processes
Switch:
- Cooperative: every process acts nice, stop running by themselves
⇒ wait for system call
⇒ use in embedded systems
- Non-cooperative: OS has to manage/stop/switch
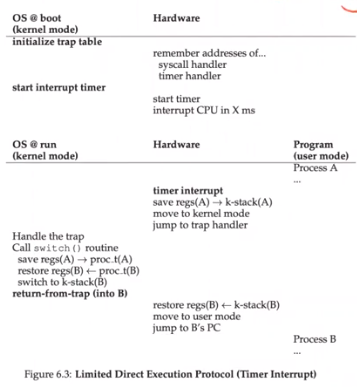
Context Switch: save and restore machine states - Timer interrupt for the non-cooperative approach to CPU scheduling
- Context switch mechanism to switch processes
- Cooperative: every process acts nice, stop running by themselves
- Create process
Chapter 3: Scheduling - Multi-level Feedback Queue
Scheduling metrics:
- performance metric → turnaround time
- fairness metric
- job = process
FIFO
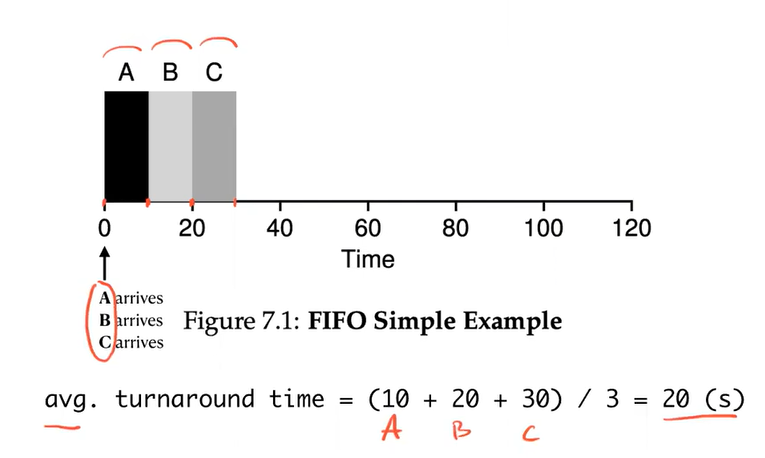
- Problem: Convoy Effect
- Usage: all processes run for the same amount of time
SJF - Shortest Job First
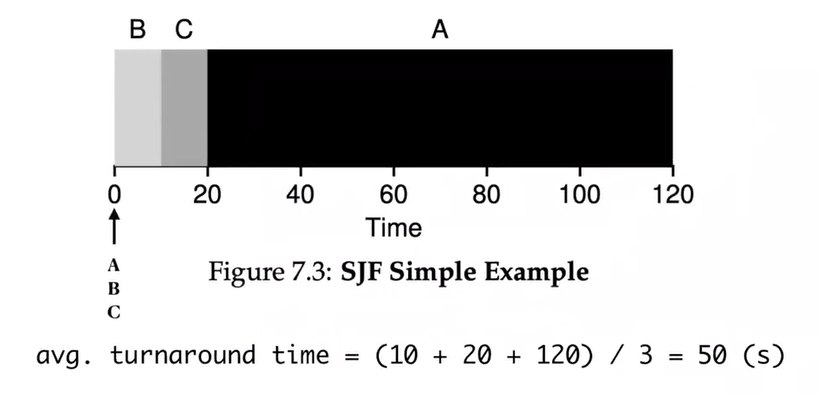
- Usage: when all jobs arrive at the same time
- Problem: when some jobs arrive later, the convoy effect happens
STCF/PSJF - Shortest Time-To-Completion/Preemptive Shortest Job First
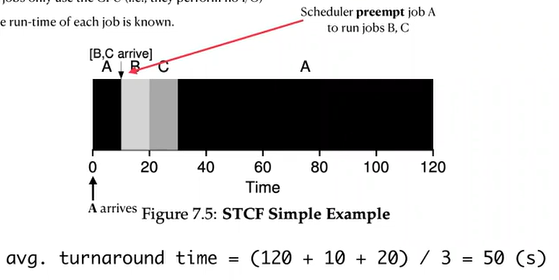
- Problem: turnaround time is great but not the response time, cause if A,B, and C all arrive at the same time, then A has to wait for B and C to complete
A new metric: Response Time
- Response time = time from when the job arrives first time to when it is scheduled
RR - Round Robin
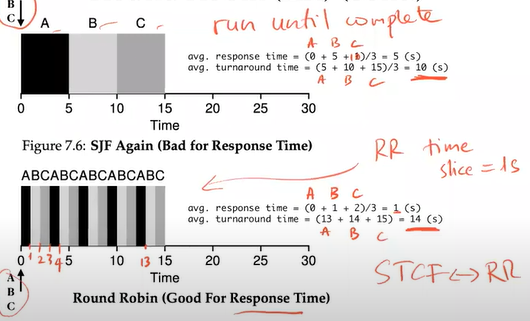
- RR runs a job for a time slice (schedule quantum) then switches to next job in the run queue
- RR is sometimes called time-slicing/time-slot
- The processes take turns to run
- Usage: better response time
- Problem: longer turnaround time
- Trade-off: The longer the time slice, the bigger the response time, the smaller turnaround time
- Making the time slice too short is problematic: suddenly the cost of context switching will dominate overall performance → make it long enough to amortize the cost of switching
⇒ Any fair policy will perform poorly on metrics such as turnaround time
Two types of schedulers
- SJF and STCF to optimize turnaround time
- RR to optimize response time
If there are I/O operations
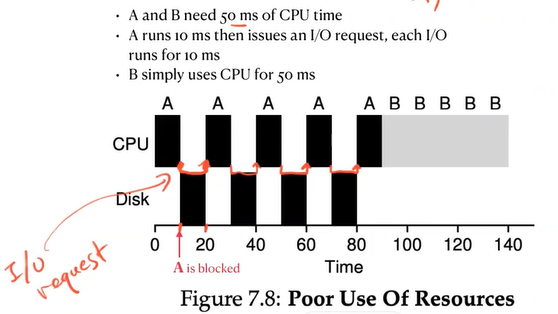
- Poor use of resources
Incorporating I/O
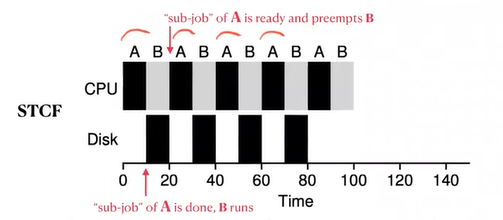
- Every I/O operation completes, sub-job is done
If there is no more oracle
- How to build an approach that behaves like SJF/STCF without knowing the runtime?
- How to use RR with a better turnaround time?
How to both:
- Minimize response time
- Minimize turnaround time
- Without prior knowledge?
Two kinds of jobs:
- Interactive: include short I/O operations
- CPU-intensive
MLFQ - Multi-Level Feedback Queue
- Has a number of distinct queues with the different priority level
- A job with higher priority is chosen to run
- Jobs on the same queue have the same priority
- Two basic rules:
- Rule 1: If PA > PB ⇒ A runs
- Rule 2: If PA = PB, A and B run in RR
- How to set priority?
- It's vary, based on observed behavior
- Learn about the processes they run
- Use the history of the job to predict the future behavior
- It's vary, based on observed behavior
Attempt 1: How to change the priority
- Rule 3: when a job enters the system, it is placed at the highest priority
- Rule 4a: if a job uses up its entire time slice while running ⇒ it P is reduced
- Rule 4b: if a job gives up CPU before the time slice is up, it stays at the same priority level
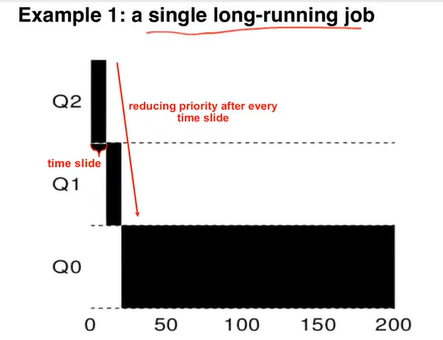
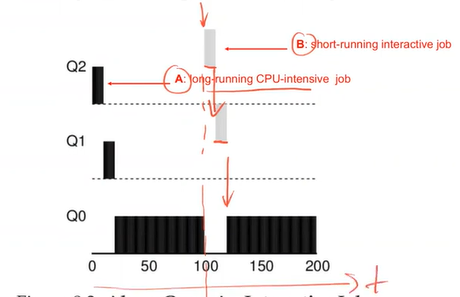
- MLFQ approximates the SJF but doesn't have to know the runtime
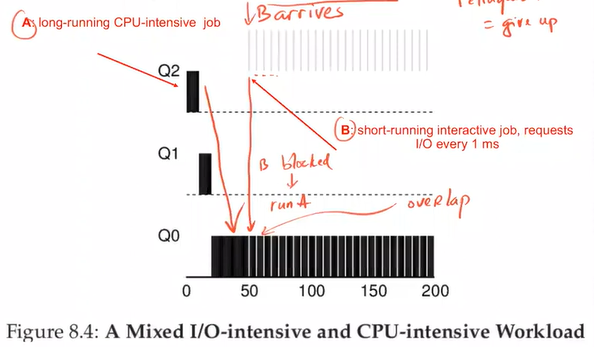
⇒ Problems:
- Starvation: too many interactive jobs consume all CPU time, long-running jobs never receive any CPU time
- A program may change its behavior over time and may not be treated like other interactive jobs
- Gaming the scheduler: a user program running for 99% of a time slice before relinquishing the CPU; thus, it could monopolize the CPU
Attempt 2: The priority boost
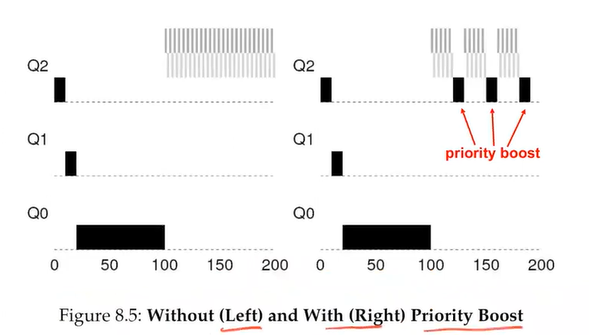
- Periodically boost the priority of all the jobs in the system
- New rule:
- Rule 5: after some time, period S, move all the jobs in the system to the topmost queue
- ⇒ Guarantee all the jobs have a chance to run
Problem: How to choose the time period S
- If S is too high, long-running jobs would starve
- If S is too low, interactive jobs may not get a proper share of CPU
Attempt 3: Better accounting
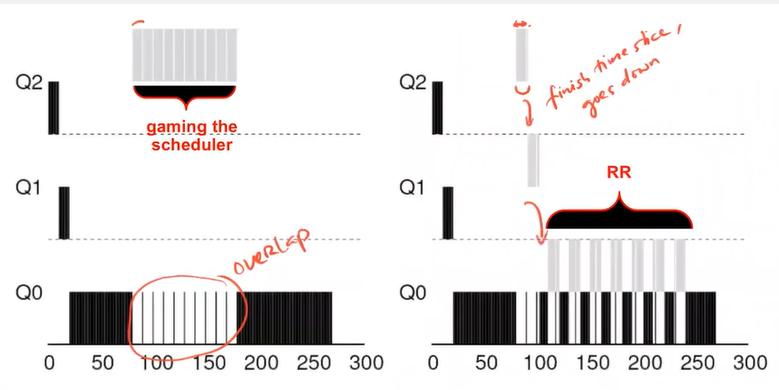
- Prevent gaming of scheduler
- Rule 4: once a job used up its time allotment at a given time, its priority is reduced
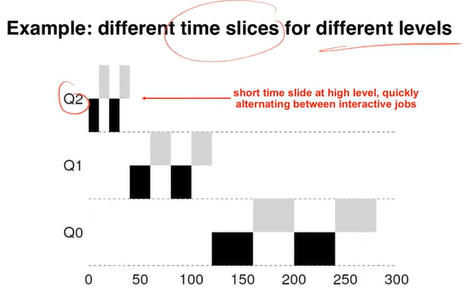
The suggestion set up for scheduler
Summary
- Many OSs use MLFQ: BSD Unix derivatives, Solaris, Windows NT, and subsequent Windows OSs
- Linux uses O(t), CFS - completely fair scheduler, BFS
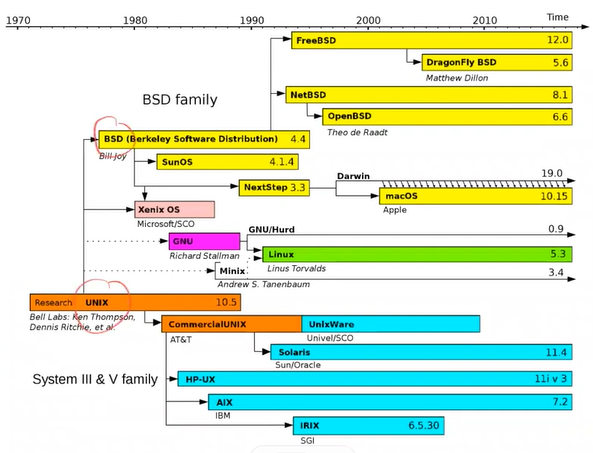
UNIX OS tree
Chapter 4: Dynamic relocation & Segmentation
- Early systems
- No memory sharing
- The program can use all memory except the space for the OS
- When the program is done, removed from the memory
- Performance is worse
- Then, multiprogramming comes up + time-sharing
- When one process performs I/O operations, other process runs
- Time-sharing: for many users to use their own space, share the computer, server
- Interactivity: response time is shorter
Requirements for these day computers:
- Multiprogramming
- Time-sharing
- Interactivity
Trivial solution
- Let process have full access to all memory
- Switching between processes by save-restore process's state
But has the issue
- Save/restore is too slow
- Memory protection
Solution: Virtual Memory - The address space
- The OS gives an illusion/abstraction to the process that it has the full memory, includes all memory states: code, stack, heap, bss...
- Virtual memory makes programs think:
- It is loaded into memory at a particular address
- It has a potentially very large address space (32 → 64 bits)
- The OS + hardware support ⇒ translates virtual address into physical address
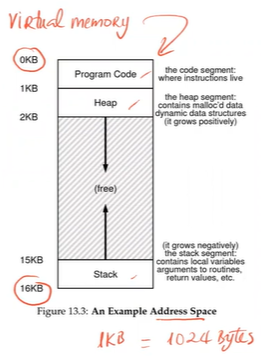
The Goals of Virtualizing Memory
- Transparency: implement virtual memory in a way that is invisible to the running program → illusion
- Efficiency in space and time
- Protection: protect processes from one another/OS itself → isolation
- Hardware-based address translation: virtual address → physical address
- Manage memory: which are free/in used; how the memory is used
- Illusion → program has it own private memory
Assumption
- User's address space must be placed contiguously in physical memory
- The size of the address space is not too big and less than the size of physical memory
- Each address space is exactly the same size
Two questions
- How to relocate the process in a way that is transparent to the process?
- How to provide an illusion of a virtual address space starting at 0?
Dynamic Relocation
Method 1: Dynamic relocation - hardware-based
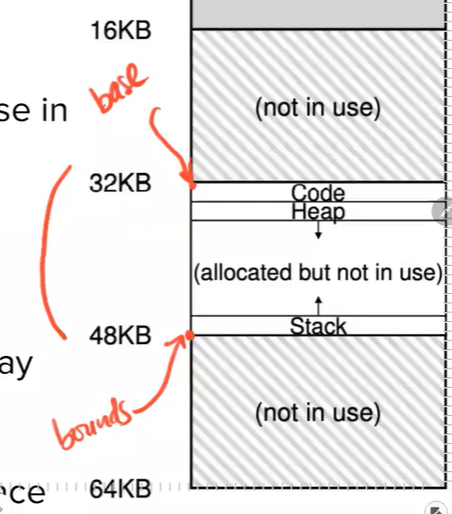
- Involve base and bound/limit registers
💡physical address = virtual address (offset) + base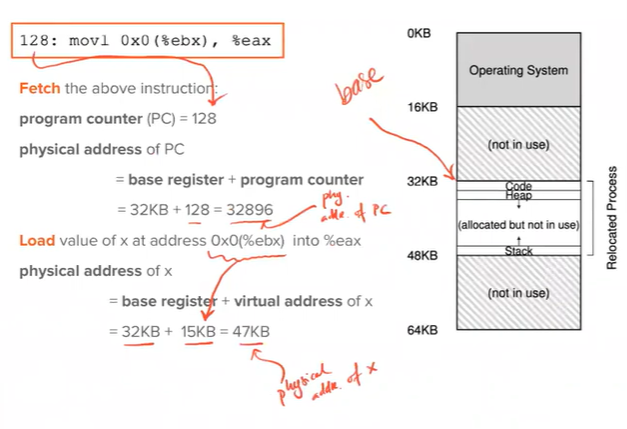
Some definitions:
- Address translation: virtual address → physical address
- Memory management unit (MMU): the part of processor that helps with address translation
- Dynamic relocation
- Relocation of the address at runtime
- Address space can even be moved after the process started running
- Update base-bound registers
Static Relocation
- Cannot move the address while running, fixed from loaded from memory
- Don't need hardware support
- Just need OS to load program to physical memory
- Not realistic
Dynamic relocation illustrations (images)
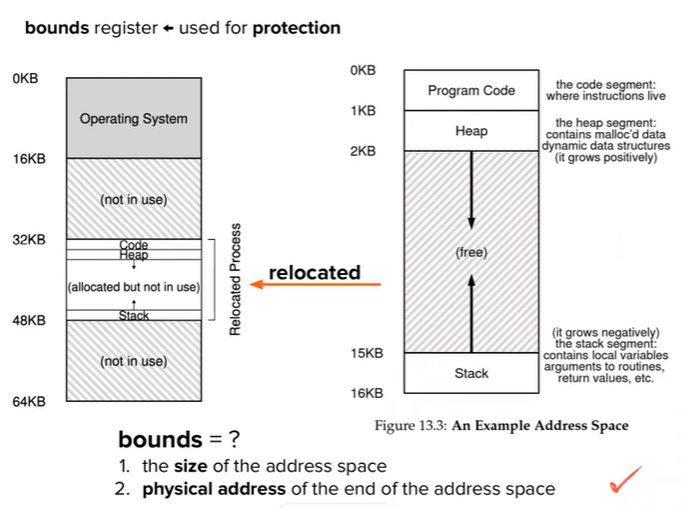


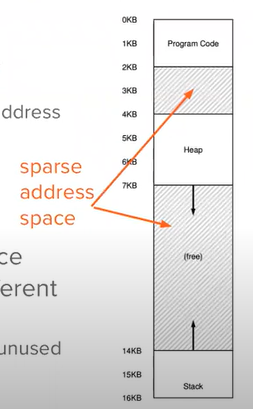
Problem with Dynamic Relocation - Internal Fragmentation
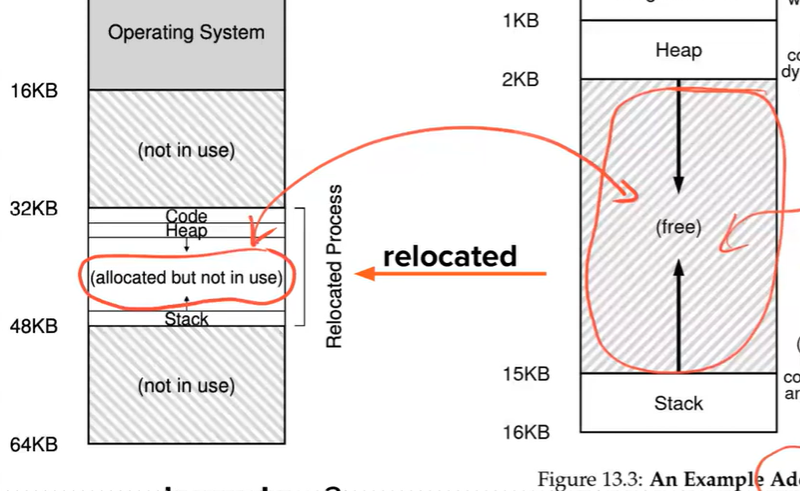
- Wasting all the space between stack and heap
- Because we put the whole virtual memory into physical memory
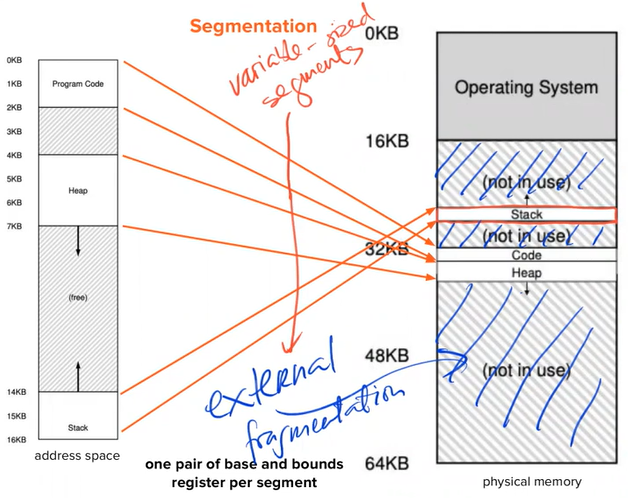
Segmentation
- Logic segment: code, stack. heap
- Allows the OS to place each one of those segments in different parts of physical memory → to avoid unused memory
- If a program tries to access an illegal address
- The OS terminates the process
- Segmentation fault showed up
- Problem:
- The space between these segments was too small to fit anything else → External Fragmentation
- Why? Result of vary sizes
 💡Relocate physical memory the same as dynamic relocation for virtual memory - fixed size
💡Relocate physical memory the same as dynamic relocation for virtual memory - fixed size⇒ Paging
Paging

- Flexibility: the OS can support the abstraction of an AP effectively, regardless of how a process uses the AP
- Simplicity: free-space management, the OS keeps the free list of all free pages
Identify segment
- Explicitly
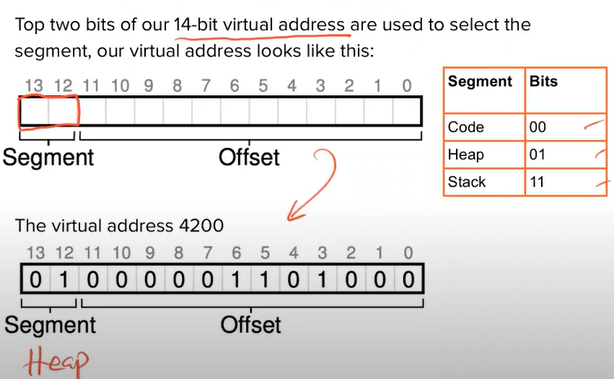
- Implicitly
- The address was generated from the PC → code segment
- The address is based on the stack or base pointer → stack segment
- Any other address → heap
- Support for Stack:
- Grow backward → need one more bit to tell that this is the stack
💡Physical address = Base - Offset
- Support for sharing - protection between processes
- Need hardware support → need more bits
- Two kinds:
- Coarse-grained → big relative large, coarse chunks
- Fine-grained → flexible with a large number of smaller segments
- But, cause more segment tables ⇒ costly
Attempt to deal with External Fragmentation
- Compact the physical memory by rearranging existing segments
- Use a free-list management algorithm
⇒ But, the EF still exists anyway, just be minimized
VPN -Virtual Page Number
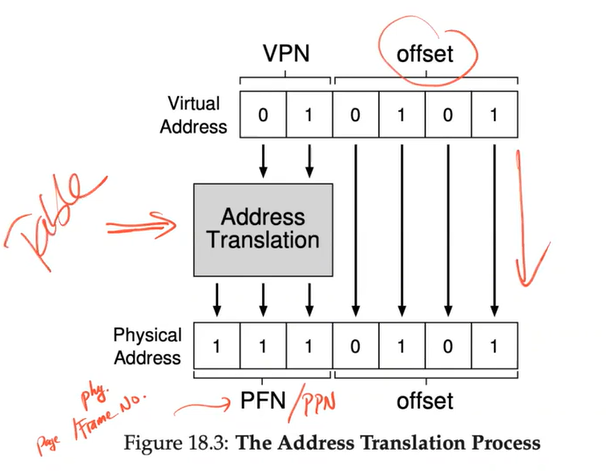

- Linear Page Table:
- Is an array
- Indexed by the VPN
- Looking up the Page-table entry PTE at that index → to find the Physical Frame Number PFN
Content of a page table

Problem with Paging:
- Also too slow
- Take too much space for page tables
- Access memory 2 times
- VA → PA
- Load data from physical memory
Chapter 5: Paging - Fast Translation (Translation-Lookaside Buffer)
- Problem: Before translation → lookup in the page table in memory → take time💡Lookaside: the technique of searching for something in a recalculated cache before attempting a more time-consuming search elsewhere
- Mapping from page number (VPN) to frame number (PFN)
- Solution: Local Version of Page Table inside the CPU cache
- L1
- L2
- TLB
Overview of the TLB
- Part of the chip's memory-management unit MMU
- Is a hardware cache of popular virtual-to-physical address translations
- Would be called "Address-translation cache"
- Only put the popular parts not the whole page table into the cache
TLB algorithm
- Calculate VPN = VA & Mask >> SHIFT
- Lookup the VPN for PTE,
- if OK → PFN, get the FN → Compute PA → Access PA
- if FAIL - a.k.a TLB miss → Look up the page table in the Memory
- get the PTE - which is a ROW of VPN → PFN
- if OK, PTE is put into the TLB cache
- if FAIL || PROTECTION FAILS → throw ERROR
- get the PTE - which is a ROW of VPN → PFN
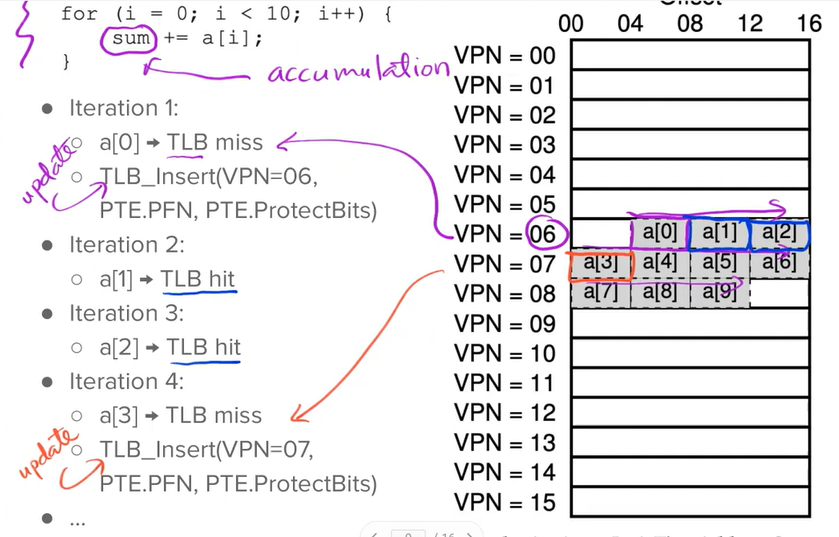
Example
- A small 8-bit AP (1) ⇒
- 16-byte pages (*) = =16 pages (2)
- (1) breaks down into:
- 4-bit VPN, why? because of (2)
- 4-bit offset, why? bytes on each page
Caching
- Use caching when possible
- Hardware caches take advantage of locality in instruction and data references
- Temporal locality: quick re-referencing
- Spatial locality: if we access x location → then x+1 can be accessed quickly later
Handling TLB miss
- Hardware-managed TLBs → Intel
- page-table base register → hardware (MMU) walks page table → update TLB → retry instruction
- Hardware-managed TLBs → MIPS, Sun's SPARC v9
- hardware raise exception → raise to kernel mode → trap handle → lookup translation in page table → update TLB using privilege instructions → return from the trap → hardware retries instruction
- infinite chain of TLB misses, ex: page table for page table and misses the TLB...
Content of the TLB
- Might have 32, 64, 128 entries, fully associative → the hardware will search entire TLB to find
- TLB entry: VPN | PFN | other bits
- Other bits:
- Valid bit
- Protection bits
- Address-space identifier
- Dirty bit
⇒ Each process has one address space, each address space has one ID

The problem of TLB: TLB can be full
⇒ Least-recently-used LRU or Random removal
Paging: Small Tables
Example of Linear Page Table
- 32-bit AP ⇒
- 4KB = page size
- 4-byte page-table entry PTE
⇒
⇒ Page table SIZE = in size
Solution 1: Bigger pages
- 32-bit AP
- 16KB = page size
- 4-byte page-table entry PTE
⇒
⇒ Page table SIZE = in size
Commonly used is 4KB or 8KB page table sizes
page size ⇒ n-bit offset
Solution 2: Paging & Segments
- Need a base and bound/limit register per segment
- Base → physical address of page table of the segment
- Bound → the size of the segment
Example for Solution 2: Hybrid
- 32-bit AP
- 4KB page size
- AP includes 4 segments ⇒ segments

Compute the Address of PTE:
- SN = (VA & SEG_Mask) >> SHIFT
- VPN = (VA & VPN_Mask) >> SHIFT
- Address of PTE = Base[SN] + (VPN * sizeof(PTE))
- Base[SN] identifies the page table for the segment
Problem with Hybrid solution
- A large but sparsely-used heap
- A lot of page table waste
- Page tables now can be of arbitrary size → External Fragmentation
Solution for Hybrid problems: Multi-Level Page Tables
- Chop up the page table → page-sized units
- If an entire page of page-table entries PTEs is invalid → Don't allocate at all
- To track if a page of a page table is valid → use the new structure called Page Directory
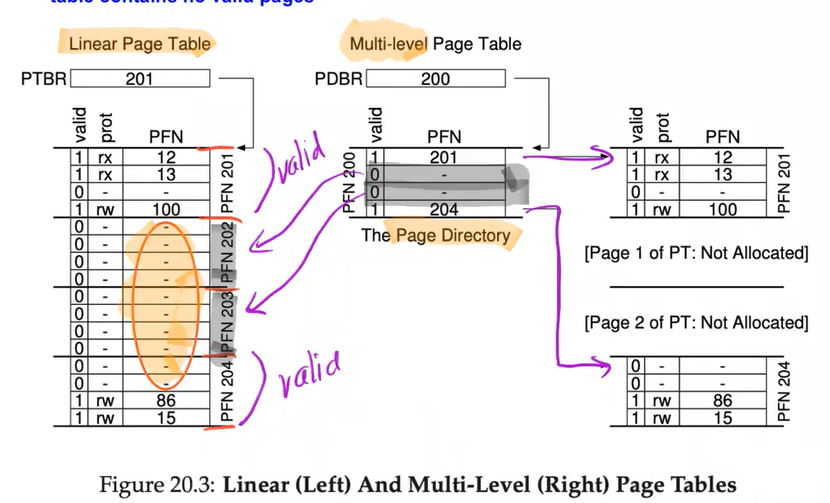
Page Directory
- A simple TWO-level table contains:
- One entry per page of the page table, it consists of a number of a PD Entries (PDE)
- a PDE has a valid bit and a page frame number PFN, similar to PTE
Pros and Cons of PD
- Pros:
- Compact and supports sparse address spaces
- Easier to manage memory
- Cons:
- On TLB miss, two loads from memory will be required: One for PD, One for PTE
- Complexity
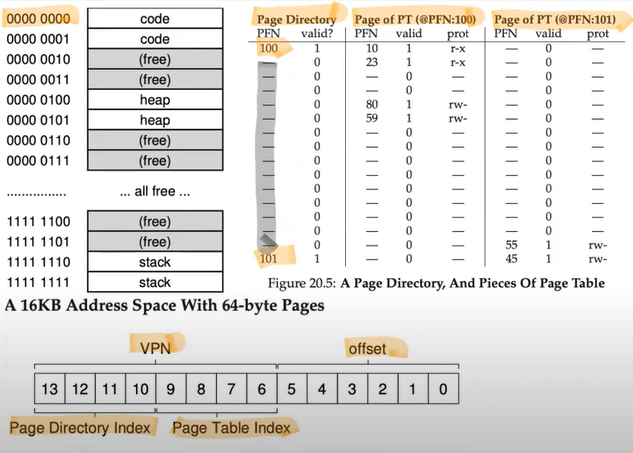
PD with more than TWO levels
Solution 4: Inverted Page Table
- A single page table that has an entry for each physical page of the system
- The entry tells us which process is using this page, and which virtual page of that process maps to this physical page
- The linear scan is expensive → A hash table is often built over the base structure speed up lookup
- Used for PowerPC chip
Solution 5: Swapping the Page Table → Disk
⇒ Place them in kernel virtual memory, then swap them into memory if it is less tight
Chapter 6:
- How to put pages on the disk? → MECHANISM
- How to choose which page to be put on the disk? → POLICY
Challenges
- How to support many concurrently-running large APs?
- How can the OS make use of a LARGER, SLOWER device to transparently provide the illusion for a large virtual AP?
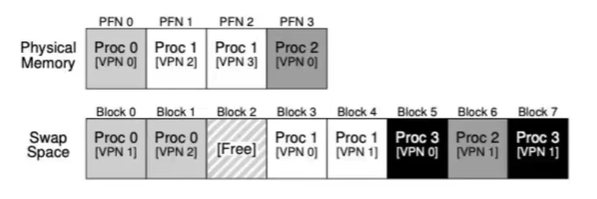
Swap Space
- Page in memory and out disk
- The OS needs to remember the disk address of a given page
- The size of swap space determines the maximum number of memory pages that can be in use by a system
The present bit
- VA → VPN → Check TLB
- If hit → Go to PA
- If miss
- Locate the Page Table in memory via Page Table Base Register
- Lookup PTE for the VPN
- Page is valid && Present bit = 1 [means it present in memory]
- Extract PFN from PTE, update TLB with new PTE
- Retry instruction
- Page is valid && Present bit = 0 → Page Fault
- Page Fault handler runs
💡A valid page means currently used page
- Page is valid && Present bit = 1 [means it present in memory]
When the page fault, the page-fault handler:

- look PTE to find the address in the disk of the page
- fetch the page → mem
- update page table, mark the page present to 1
- update PFN
- retry instruction
What if memory is full
- Before page in, OS page out one or more pages to make room for new pages💡Page-replacement Policy
- Rules which one to be paged out
When the replacements really occur
- To keep a small amount of memory free, most OSs have some kind of High/Low Watermark HW/LW to help decide when to start evicting pages from memory💡Swap Daemon or Page Daemon (Daemon is a program run in background)
Beyond Physical Memory Policies
Cache management
- Main memory hold a subset of all the pages in the system → memory can be viewed as a cache for Virtual Memory Pages
- Minimize cache misses
- Maximize cache hits
Average Memory Access Time - AMAT
- : the percentage of miss
- : cost of accessing memory
- : cost of accessing disk
Example
- Sequence of memory references: hit, hit, hit, miss, hit, hit, hit, hit, hit, hit
-
-
-
⇒
If hit rate = 99.9% ⇒
The Optimal Replacement Policy

⇒ ONE BIG Problem: we don't know about the FUTURE
FIFO Policy
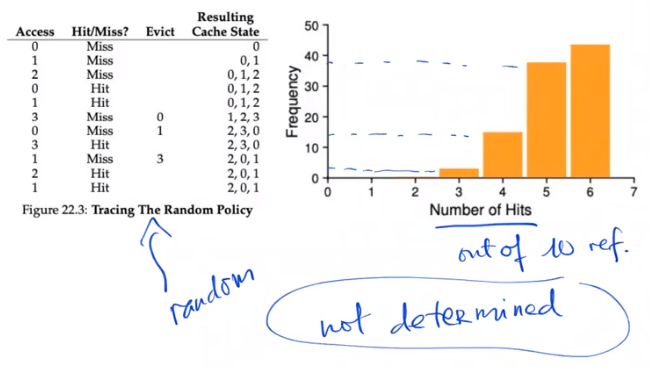
RANDOM Policy

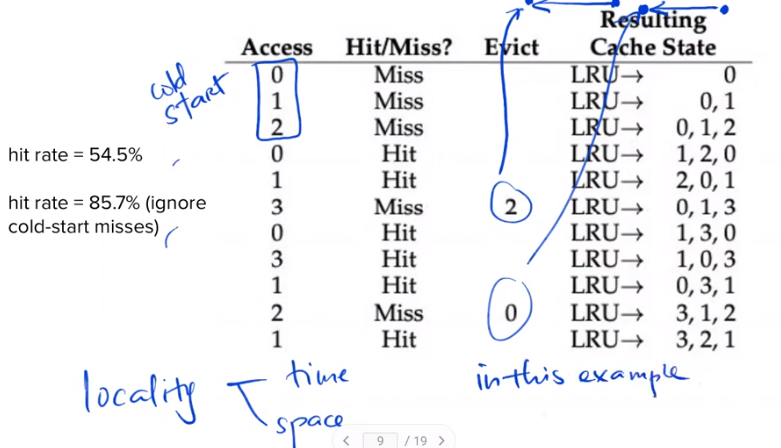
LRU Policy
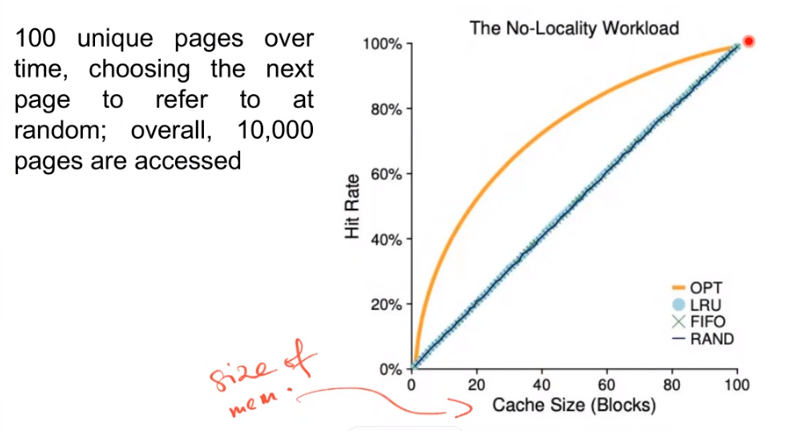
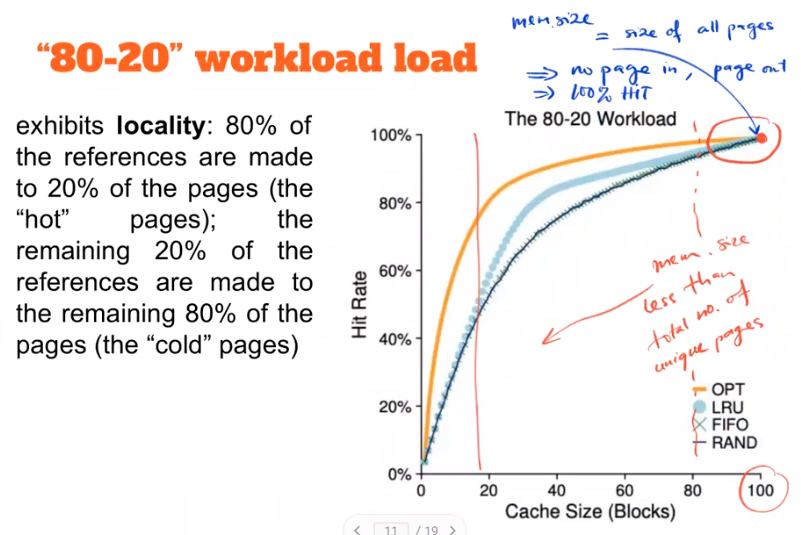
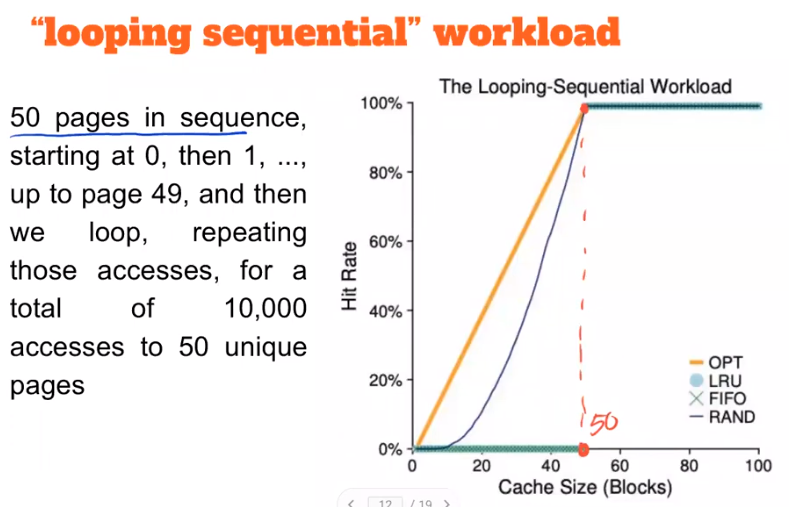
How to implement HISTORICAL algorithms - LRU
- Timer field added to
- per process page table
- separate array in memory with one entry per physical page of the system
- Scanning a huge array of times to find absolute-least-recently-used page → EXPENSIVE
Solution: Approximating LRU
- Clock hand point to some particular page to begin
- Go round the clock, search for next candidate to evict, use bit = 0
- Change use bit to 0 after visited by clock hand
Considering Dirty Pages
- If a page has been modified → dirty → if eviction ~ writing modified data into disk → more expensive
- System refers to evict clean pages
- Clock algorithm evicts modified bit = 0 and use bit = 0 pages first
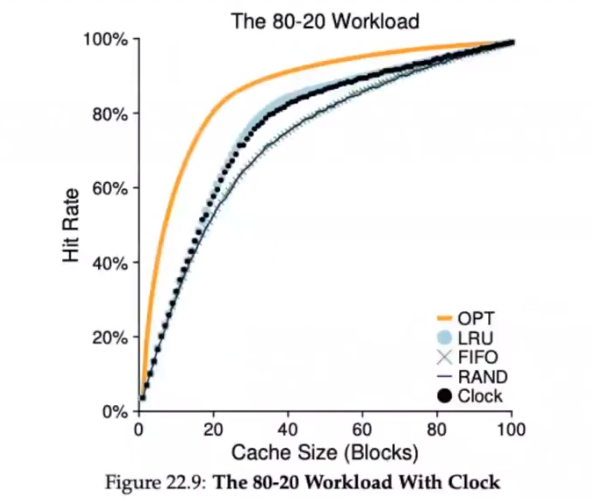
Other VM Policies
Thrashing
- Page Selection Policy
- Demand Paging: based on the need
- Prefetching: need to know what it is
- Clustering/Grouping writes
What if the demand exceeds the available PM?
Solution:
- Reduce the number of concurrent process → admission control
- OR out-of-memory killer daemon (Linux)
Chapter 7: Concurrency Introduction
Threads
- Parallelism
- Avoid blocking program progress due to show I/O operations
- Threads share an address space → easy to share data
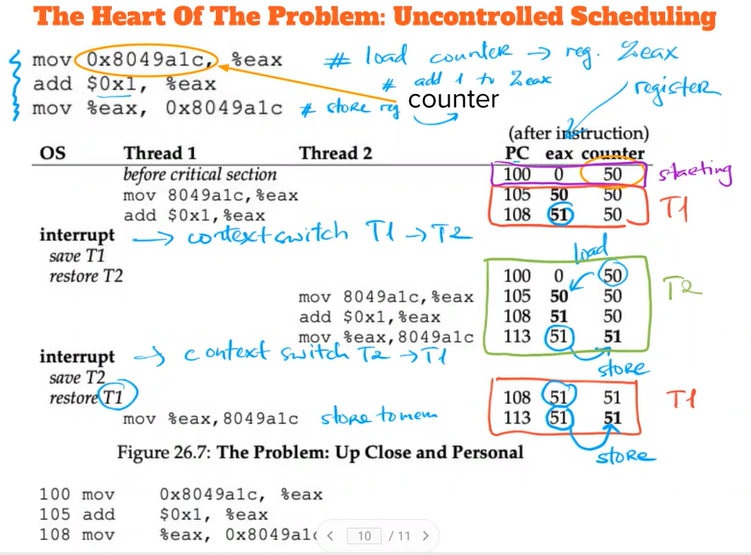
Problem with Threads: INTERRUPT - Uncontrolled Scheduling

Locks
- Idea: lock the critical block for the section until it is finished → No more Interrupt
Basic Idea
lock_t mutex; // mutual exclusion
...
lock(&mutex);
n = n + 1;
unlock(&mutex);Pthread locks
pthread_mutex_t lock = PTHREAD_MUTEX_INIT;
pthread_mutex_lock(&lock);
n = n + 1;
pthread_mutex_unlock(&lock);Evaluating locks
- Correctness: it should work - can it prevent multiple threads from entering
- Fairness: each thread contending (tranh giành) for the lock get a fair shot at acquiring it
- Starve: one/many threads never obtain the lock
- Performance: time overheads → should not waste the CPU cycles
Solution 1: Controlling Interrupts
void lock(){
DisableInterrupts(); // disable interrupt before entering CS
}
void unlock(){
EnableInterrupts();
}- Problems:
- A thread can monopolize the processor by keeping the lock
- Not work on multiprocessors
- Interrupt losts
- Inefficient
Solution 2: A failed attempt - Just using loads/stores
typeof struct __lock_t { int flag; } lock_t;
void init(lock_t *mutex) {
mutex -> flag = 0; // 0: free; 1: busy
}
void lock(lock_t *mutex) {
while (mutex -> flag == 1) {
// do nothing
}
mutex -> flag = 1;
}
void unlock(lock_t *mutex) {
mutex -> flag = 0;
}Problems:
- shared variable → cause incorrect setting
- Spin and wait → wasting CPU cycles
Solution 3: Building working spinlocks with test-and-set
- Hardware support → test-and-set (atomic exchange) instruction
- Require a preemptive scheduler
int TestAndSet(int *old_ptr, int new) {
int old = *old_ptr;
*old_ptr = new;
return old;
}
typedef struct __lock_t { int flag; } lock_t;
void init(lock_t *lock) {lock -> flag = 0;}
void lock(lock_t *lock) {
while(TestAndSet(&lock->flag, 1) == 1) {
// do nothing
}
}
void unlock(lock_t *lock) { lock->flag = 0; }Solution 4: Compare-and-swap
int CompareAndSwap(int *ptr, int expected, int new) {
int original = *ptr;
if (original == expected) {
*ptr = new;
}
return original;
}
void lock(lock_t *lock) {
while (CompareAndSwap(&lock->flag, 0, 1) == 1) {
// do nothing
}
}Solution 5: Load-linked and store-conditional
int LoadLinked(int *ptr) {
return *ptr;
}
int StoreConditional(int *ptr, int value) {
if (no update to *ptr since LoadLinked to this address) {
*ptr = value;
return 1;
} else {
return 0;
}
}
void lock(lock_t *lock) {
while(1) {
while (LoadLinked(&lock->flag, 1) == 1) { // do nothing}
if (StoreConditional(&lock->flag, 1) == 1) return;
// only update when there is no update between load&store
// if 1: all done, else: try again
}
}Solution 6: Fetch-and-add
int FetchAndAdd(int *ptr) {
int old = *ptr;
*ptr = old + 1;
return old;
}
typedef struc __lock_t { int ticket, turn; } lock_t;
void lock_init(lock_t *lock) {
lock -> ticket = 0; lock -> turn = 0;
}
void lock(lock_t *lock) {
int myturn = FetchAndAdd(&lock->ticket); // increase the ticket, return previous
while(lock->turn !== myturn) { // do nothing }
}
void unlock(lock_t *lock) {
lock -> turn = lock -> turn + 1
}- Solve the starvation problem
- Spin locks are quite inefficient
- N threads → (N - 1) time slices may be wasted
⇒ NEED OS supports
Solution 7: yield()
void lock() {
while(TestAndSet(&flag, 1) == 1) {
yield(); // give up the CPU
}
}- yield() → give up the CPU and let another thread run → reschedules itself
- problems
- run-and-yield for big number of threads → costly
- starvation problem
Solution 8: using queues → sleeping instead of spinning
typedef struct __lock_t {int flag, guard; queue_t *q;} lock_t;
void init(lock_t *m) {
m -> flag = 0;
m -> guard = 0;
queue_init(m -> q);
}
void lock(lock_t *m) {
while(TestAndSet(&m->guard, 1) == 1) {
// acquire guard lock by spinning
}
if (m -> flag == 0) { m -> flag = 1; m -> guard = 0}
else {
queue_add(m -> q, gettid()); // put pid -> queue and wait
m -> guard = 0;
park(); // put thread to sleep
}
}
void unlock(lock_t *m) {
while(TestAndSet(&m->guard, 1) == 1) {
// acquire guard lock by spinning
}
if (queue_empty(m->q)) { m -> flag = 0; // let go of lock, not need anymore}
else {
unpark(queue_remove(m->q)); // put pid -> queue and wait
}
m -> guard = 0; park();
}- More efficient compares to spinlock
- Solve starvation problem
- Maybe race condition before call to park() ⇒ solved by setpark() - interrupts unpark() before park() is called